A Simple Guide to Webscraping With Python .

Photocredit to me and my amazing Canva skills.

Webscraping is the process of pulling data from websites, typically using a script. Webscraping is a wonderful thing: like many other automations, you can save hours (or more) of work. I’ve found this skill to be incredible useful, as I’ve applied it to many different projects. In this tutorial, I’ll show you how to write a Python script that creates a CSV file of data from a fake online bookstore. This tutorial assumes that you understand the basics of Python (e.g., loops, functions, variables) and know a little about websites (i.e., HTML). If you do not, please go to this for a Python tutorial and here for HTML help before continuing.
Legal disclaimer: while webscraping is usually legal, please follow all applicable laws and be a good citizen of the internet.
What we’re building
Some websites forbid webscraping or otherwise are difficult to scrape. Because of this, we will scrape www.books.toscrape.com, as this site was set up for this purpose. The website is a mock online book store, with a list of books that includes prices, ratings, and inventory. Go to the site and play around with it.
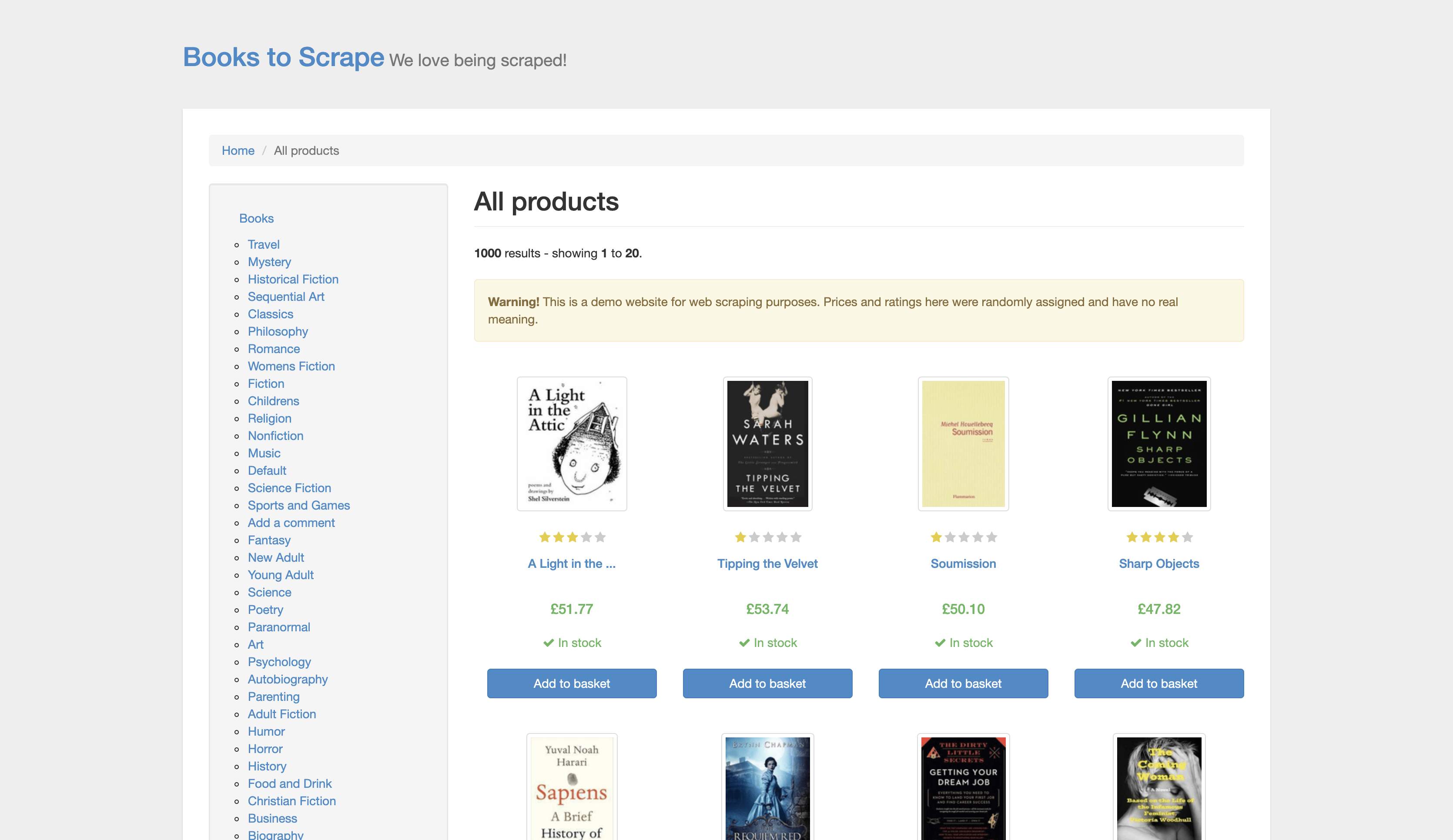
By the end, we will have a file books.csv containing the price, title, rating, and inventory status of the first 50 books on the site. Let’s get rolling!
Step 1. Getting Started
Create a directory (e.g, ‘scraping’) and navigate into it.
We’ll be using Python 3.6, because it’s my favorite version. First, let’s install beautifulsoup4, the standard library for parsing HTML pages. (You may need to use pip3 or apt-get, depending on your OS.)
foo@bar:~$ pip3 install beautifulsoup4
Next, we will do the same for requests, which is how we will pull the HTML page.
pip3 install requests
Now, create a file named scrape.py. We will write our code in here. At the top of the file, put the following:
import requests
from bs4 import BeautifulSoup
These lines load the requests and beautifulsoup libraries, making them available to us later on. Let’s now get the website page using the requests library. The get method returns the webpage (along with other info), and we can get the website content through the following:
import requests
from bs4 import BeautifulSoup
url = "http://books.toscrape.com/"
page = requests.get(url)
print(page.content)
Run our script by doing python3 scrape.py in terminal. You should see the page’s HTML being printed.
Before we write more code, we need to understand the HTML we’ll be parsing.
Step 2. Understand the structure of the website
Let’s dig into the HTML of the website so we can figure out how to get the information we want. As you should know by now, websites are formed from a nested tree of tags, like <h1>. Using the chrome inspector, we can see that the categories column has a class sidebar.
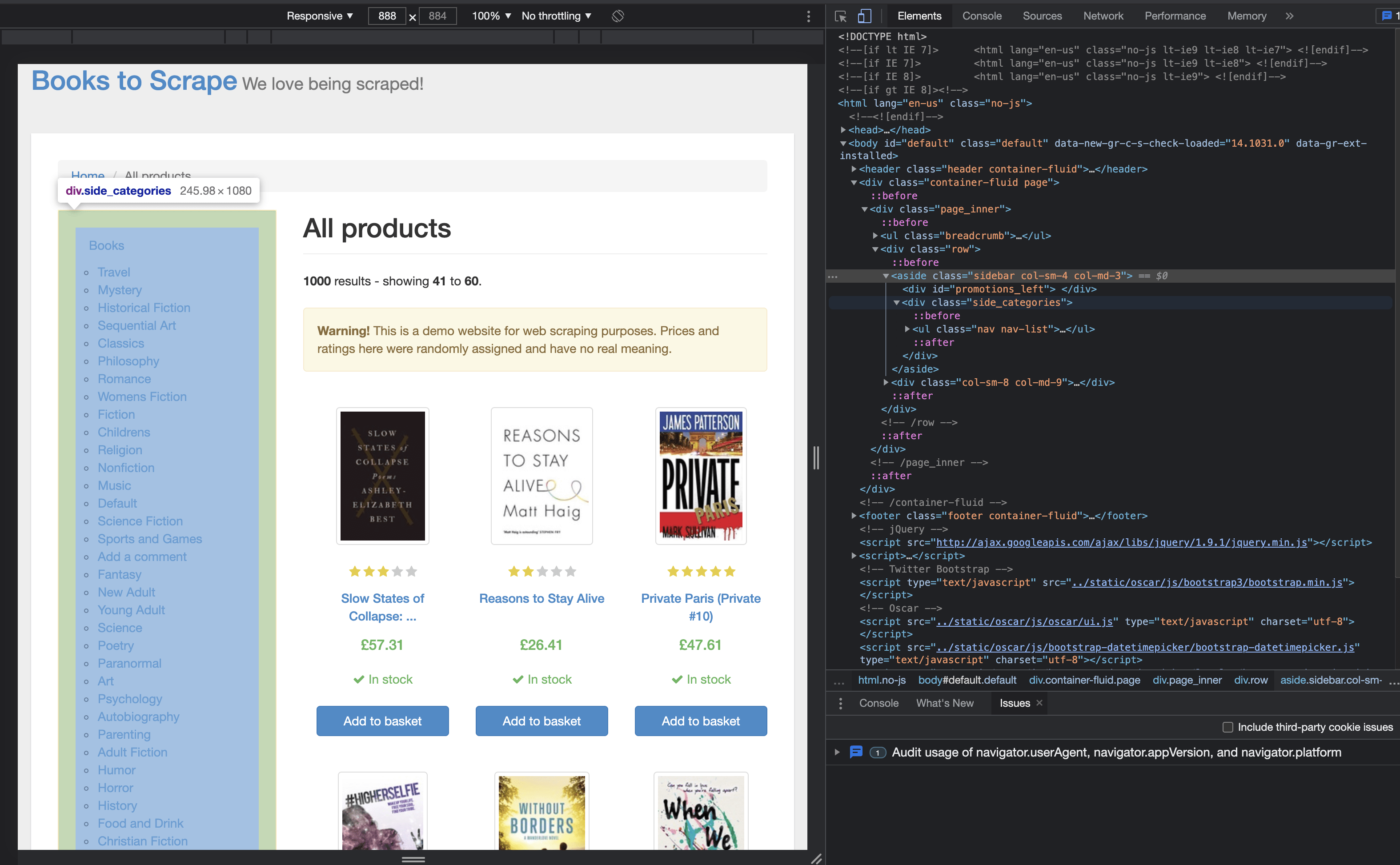
Likewise, we see that the book info we need is in a <article> tag with class product_pod.
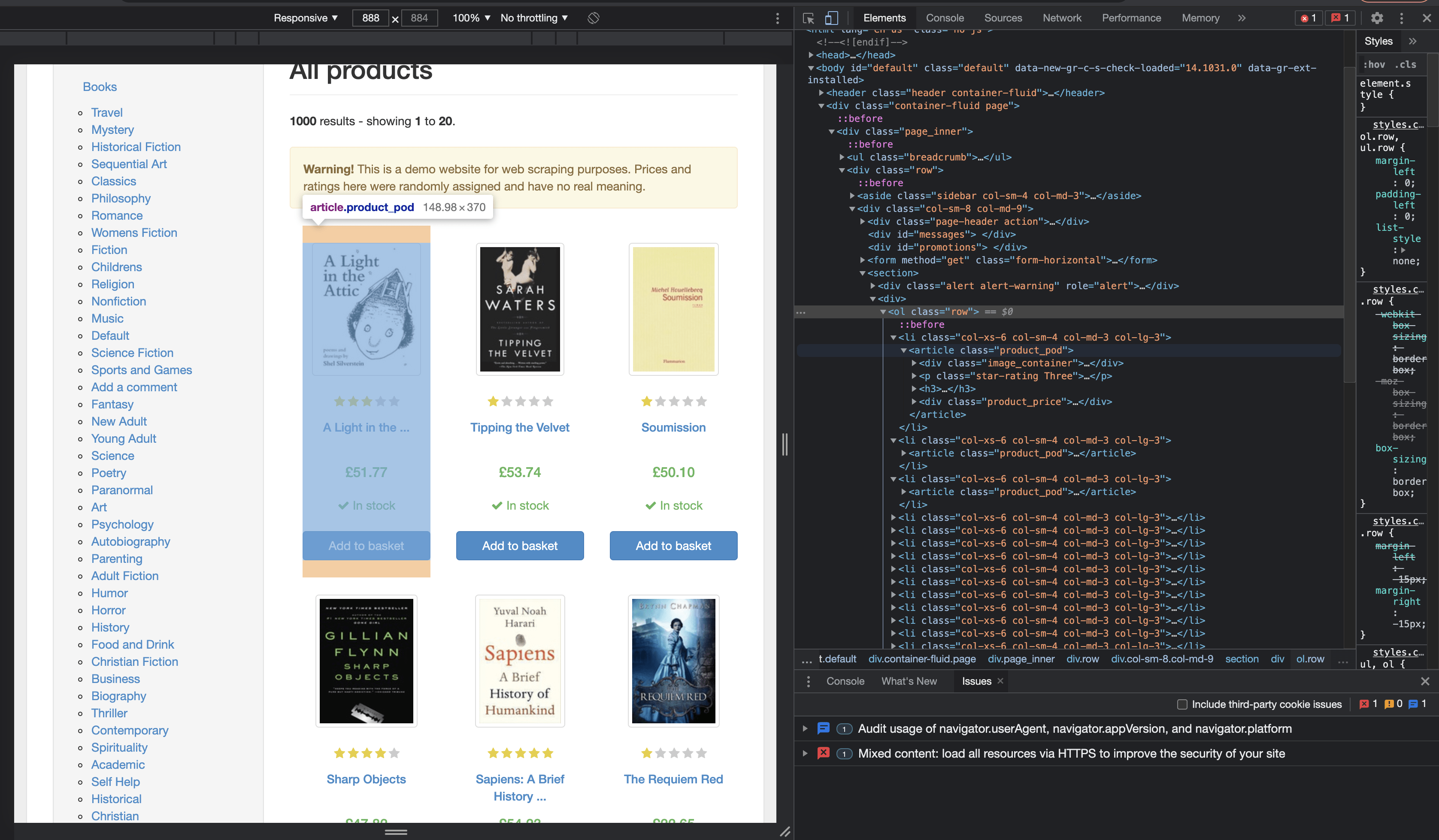
Let’s take a closer look at one of these book elements.
<li class="col-xs-6 col-sm-4 col-md-3 col-lg-3">
<article class="product_pod">
<div class="image_container">
<a href="catalogue/soumission_998/index.html"><img src="media/cache/3e/ef/3eef99c9d9adef34639f510662022830.jpg" alt="Soumission" class="thumbnail"></a>
</div>
<p class="star-rating One">
<i class="icon-star"></i>
<i class="icon-star"></i>
<i class="icon-star"></i>
<i class="icon-star"></i>
<i class="icon-star"></i>
</p>
<h3><a href="catalogue/soumission_998/index.html" title="Soumission">Soumission</a></h3>
<div class="product_price">
<p class="price_color">£50.10</p>
<p class="instock availability">
<i class="icon-ok"></i>
In stock
</p>
<form>
<button type="submit" class="btn btn-primary btn-block" data-loading-text="Adding...">Add to basket</button>
</form>
</div>
</article>
</li>
From this, we can deduce the following:
- The title of the book can be found in the image alt tag, or in the h3 tag
- The rating is represented as a class name (
One,Two, and so on) - The price is in a p tag with the class name of
price_color - The inventory status is found in a p tag with class name
instock availability
HTML isn’t meant to be read by users, per se. Instead, the browsers render the HTML code into text, images, and all the other components of websites. Thus, we have to carefully select the elements that have the data that we want. Thankfully, beautifulsoup makes this easy.
Step 3. Extract the data from the HTML
BeautifulSoup takes a webpage and converts the HTML into a structure that is easily parsible. For example, we can get the title of the webpage through the following:
soup = BeautifulSoup(page.content, 'html.parser')
print(soupe.title) # <title> All products | Books to Scrape - Sandbox </title>
Now we can a list of the books. Using soup.find_all(), we can get all article elements with class “product_pod”.
for listing in soup.find_all("article", {"class": "product_pod"}):
print(listing)
This should print out the raw HTML for each book element. Now let’s get the actual data we want, starting with the rating. We can grab the first p tag with listing.p. To get the second class we can do listing.p['class'][1] (listing.p['class'] returns a list of classes for this p).
for listing in soup.find_all("article", {"class": "product_pod"}):
rating = listing.p['class'][1] # "One"
We can get the image element through listing.img and the alt attribute through img['alt'], which has the book title. (Note, we could just as easily use the h3 tag.)
for listing in soup.find_all("article", {"class": "product_pod"}):
rating = listing.p['class'][1]
title = listing.img['alt']
Remember how the price of each book has the class “price_color”? Using listing.find returns the price element, whereas .text enables us to grab just the text we want (not the HTML).
for listing in soup.find_all("article", {"class": "product_pod"}):
rating = listing.p['class'][1]
title = listing.img['alt']
price = listing.find(attrs={"class", "price_color"}).text
For the last piece of data we want, we will say a book is in stock if we see the “instock” class. Note, text.strip() just formats the data in a way that is nice for us.
for listing in soup.find_all("article", {"class": "product_pod"}):
rating = listing.p['class'][1]
title = listing.img['alt']
price = listing.find(attrs={"class", "price_color"}).text
inStock = "yes" if listing.find(attrs={"class", "instock"}).text.strip() == 'In stock' else "no"
Finally, we need to store the data we parsed. Let’s create a dictionary, where the keys are the book number and the values are the rating, title, price, and inStock status for that book $i$.
data = {}
for (i, listing) in enumerate(soup.find_all("article", {"class": "product_pod"})):
rating = listing.p['class'][1]
title = listing.img['alt']
price = listing.find(attrs={"class", "price_color"}).text
inStock = "yes" if listing.find(attrs={"class", "instock"}).text.strip() == 'In stock' else "no"
data[i] = [rating, title, price, inStock]
Step 4. Write the data to a CSV file
To be able to access this data later, we will output the data into a CSV file. Python has support for CSV functionalities in the csv module, so import it at the top of the file. I’m going to show you the code first and then explain it line-by-line:
with open('data.csv', 'w+') as f:
w = csv.writer(f)
w.writerow(["rating", "title", "price", "inStock"])
w.writerows(data.values())
The first line creates an empty file data.csv and makes it available to us in the variable f. We then create a writer object, a handy way to write to a csv file. We then write the header of the file using w.writerow(). Lastly, we write all of the rating, price, title, and inventory status using writerows().
Step 5. Run our script
With our code written, we can now run it and extract the book data from the website. To run our script, use the following:
python3 scrape.py
Once done, you should have a file that looks like this:
rating,title,price,inStock
Three,A Light in the Attic,£51.77,yes
One,Tipping the Velvet,£53.74,yes
One,Soumission,£50.10,yes
Four,Sharp Objects,£47.82,yes
Five,Sapiens: A Brief History of Humankind,£54.23,yes
One,The Requiem Red,£22.65,yes
Four,The Dirty Little Secrets of Getting Your Dream Job,£33.34,yes
Three,The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull,£17.93,yes
Four,The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics,£22.60,yes
One,The Black Maria,£52.15,yes
Two,"Starving Hearts (Triangular Trade Trilogy, #1)",£13.99,yes
Four,Shakespeare's Sonnets,£20.66,yes
Five,Set Me Free,£17.46,yes
Five,Scott Pilgrim's Precious Little Life (Scott Pilgrim #1),£52.29,yes
Five,Rip it Up and Start Again,£35.02,yes
Three,"Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991",£57.25,yes
One,Olio,£23.88,yes
One,Mesaerion: The Best Science Fiction Stories 1800-1849,£37.59,yes
Two,Libertarianism for Beginners,£51.33,yes
Two,It's Only the Himalayas,£45.17,yes
Here is our final code (a masterpiece, if I do say so myself):
import requests
from bs4 import BeautifulSoup
url = "http://books.toscrape.com/"
page = requests.get(url)
data = {}
for (i, listing) in enumerate(soup.find_all("article", {"class": "product_pod"})):
rating = listing.p['class'][1]
title = listing.img['alt']
price = listing.find(attrs={"class", "price_color"}).text
inStock = "yes" if listing.find(attrs={"class", "instock"}).text.strip() == 'In stock' else "no"
data[i] = [rating, title, price, inStock]
with open('data.csv', 'w+') as f:
w = csv.writer(f)
w.writerow(["rating", "title", "price", "inStock"])
w.writerows(data.values())
Conclusion
Congrats! No matter whether or not you understood everything that was going on, you have sucessfully written your first webscraping program. Scraping is a powerful tool, and it’s often the first step in other work pipelines, like collecting data for machine learning.
While we accomplished a lot, we can do better. Currently, we are only scraping the homepage of the website, which is the first 50 books. Can you get the other 950 books? (Hint: notice how the second page of the book catalogue has the url http://books.toscrape.com/catalogue/page-2.html, the third page is http://books.toscrape.com/catalogue/page-3.html, and so on. Can you scrape multiple pages with our code?)
